2009-12-15 – N900 – first impressions
Collabora was kind enough to buy N900s for all its employees. Yay! I got mine on Friday and has been playing around with it quite a bit. It’s very shiny and the user experience is a lot better than the N810. There are a few graphical glitches, it seems it’s XDamage damaging a bit of a window and it’s just not quick enough to repaint. Not a problem, and it has far fewer instances of just hanging for half a second which my iPhone has. That is, it hasn’t had any of those yet.
The screen is good, but resistive. Takes a short while to get used to when you’re used to capacative, but it’s not a problem at all. The keyboard is good, but I need to map something as the compose key. Having US/UK key caps and using the Norwegian layout is a bit confusing. Not really the fault of the device though.
The web browser is generally quite good. The gestures take a bit of time to get used to, but they’re not hard as such. Some of the default “applications” are implemented as just links to the web pages of services like Twitter, which is a bit silly as you don’t even get a version that’s optimised for the N900. They’re not useless, but they are absolutely nowhere near a real application. Also, the “Store” (Ovi Store) application/web page says “coming soon”, which is quite odd.
I’m not sure if I can change the selection of applications on the default application list, but modifying the desktop is easy. There seems to be few themes and background images available so far, at least in anything resembling official repositories. Hopefully this will improve over time.
So far, I haven’t actually written any code for the N900. I have some applications I want to write, mostly widget-style apps like “when does the next bus home leave from a bus stop close to me and where is the bus stop”, but also some other ones.
Battery life is not great. It almost did 48 hours today with a bit of use underway, and I did charge it before it ran completely out, but when I’m used to closer to a week, it’s not that good. Camera seems good and is quite fast, I think it took less than five seconds from opening the camera shutter until I had taken a picture. Shutter delay is quite bad at about a third or half a second, but this is a mobile phone (or mobile computer, as Nokia likes to call it) and not a DSLR, so I’m quite happy with it.
As a phone, it seems fine so far. I can make calls and accept calls and there’s no noticeable problems with it. It also functions as a modem/DUN over bluetooth, which is quite useful.
Build quality seems good, there’s a good feeling when sliding the keyboard in and out, but only time will tell how good it actually is.
So far, I’m happy with it, it’s a big step up from my previous UK phone (which is a Nokia E70; my iPhone is a 2G phone so I can’t use it here with the provider I’m using). Hopefully I’ll post more happy stories about it in the days to come.
2009-12-03 – ekey happiness
In my last post about the ekey, I complained about two things: memory leak in the server and missing reconnects if the client was disconnected for any reason. I’ve meaning to blog about the follow up for while, but haven’t had the time before now.
Quite quickly after my blog post, Simtec engineers got in touch on IRC and we worked together to find out what the memory leak problem was. They also put in the reconnect support I asked for. All this in less than a week, for a device which only cost £36.
To make things even better, they picked up some other small bug
fixes/requests from me, such as making ekeyd-egd-linux just Suggest
ekeyd and the latest release (1.1.1) seems to have fixed some more
problems.
All in all, I’m very happy about it. To make things even better, Ian
Molton (of Collabora) has been busy fixing up virtio_rng in the
kernel and adding EGD support (including reconnection support) to qemu
and thereby KVM. Hopefully all this hits the next stable releases and
I can retire my egd-over-stunnel hack.
2009-11-05 – Package workflow
As 3.0 format packages are now allowed into the archive, I am thinking about what I would like the workflow to look like and hoping one of them fits me.
For new upstream releases, I am imaginging something like:
-
New upstream version is released.
-
git fetch+ merge into upstream branch. -
Import tarballs, preferably in their original format (bz2/gzip), using
pristine-tar. -
Merge upstream to debian branch. Do necessary fixups and adjustments. At this point, the upstream..debian branch delta is what I want to apply to the upstream release. The reason I need to apply this delta is so I get all generated files into the package that’s built and uploaded.
-
The source package has two functions at this point: Be a starting point for further hacking; and be the source that buildds use to build the binary Debian packages.
For the former, I need the git repository itself. It is increasingly my preferred form of modification and so I consider it part of the source.
For the latter, it might be easiest just to ship the
orig.tar.{gz,bz2}and the upstream..debian delta. This does require the upstream..debian delta not to change any generated files, which I think is a fair requirement.
I’m not actually sure which source format can give me this. I think
maybe the 3.0 (git) format can, but I haven’t played around with it
enough to see. I also don’t know if any tools actually support this
workflow.
2009-11-02 – Distributing entropy
Back at the Debian barbeque party at the end of August, I got myself
an EntropyKey from the kind folks at Simtec. It has
been working so well that I haven’t really had a big need to blog
about it. Plug it in and watch
/proc/sys/kernel/random/entropy_avail never empty.
However, Collabora, where I am a sysadmin also got one. We are using a few virtual machines rather than physical machines as we want the security domains, but don’t have any extreme performance needs. Like most VMs they have been starved from entropy. One problem presents itself: how do we get the entropy from the host system where the key is plugged in to the virtual machines?
Kindly enough the ekeyd package also includes ekeyd-egd-linux
which speaks EGD, the TCP protocol the Entropy Gathering Daemon
defined a long time ago. ekeyd itself can also output in the same
protocol, so this should be easy enough, or so you would think.
Our VMs are all bridged together on the same network that is also exposed to the internet and the EGD protocol doesn’t support any kind of encryption, so in order to be safe rather than sorry, I decided to encrypt the entropy. Some people think I’m mad for encrypting what is essentially random bits, but that’s me for you.
So, I ended up setting up stunnel, telling ekeyd on the host to
listen to localhost on a given port, and stunnel to forward
connections to that port. On each VM, I set up stunnel to forward
connections from a given port on localhost to the port physical
machine where stunnel is listening. ekeyd-linux-egd is then told to
connect to the port on localhost where stunnel is listening. After a
bit of certificate fiddling and such, I can do:
# pv -rb < /dev/random > /dev/null
17.5kB [4.39kB/s]
which is way, way better than what you will get without a hardware RNG. The hardware itself seems to be delivering about 32kbit/s of entropy.
My only gripes at this point is that the EGD implementation could use a little bit more work. It seems to leak memory in the EGD server implementation. Also, it would be very useful if the client would reconnect if it was disconnected for any reason. Even with those missing bits, I’m happy about the key so far.
2009-07-02 – Airport WLAN woes
Dear whoever runs the Telefonica APs in both Rio de Janeiro and Sao Paulo airports: Your DNS servers are returning SERVFAIL and has been doing so for quite a while. This is not helpful, perhaps you should set up some monitoring of them?
2009-06-19 – Rendering GPX files using libchamplain and librest
A little while ago, I read robster’s post about librest, and it looked quite neat. I have had a plan for visualising GPX files for quite a while, hopefully with something that allows you to look at data for various bits of a track, like speed and the time you where there, but for various reasons, I haven’t had the time before.
Last night, I took a little time to glue librest and libchamplain together. libchamplain is a small gem of a library, quite nice to work with and with the 0.3.3 release, it got support for rendering polygons. The result is in this screenshot:
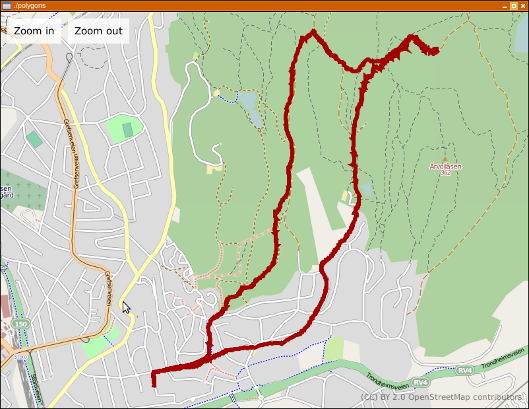
This is about 160 lines of C, all included.
2008-12-17 – varnishlog's poor man's filtering language
Currently, varnishlog does not support very advanced filtering. If
you run it with -o, you can also do a regular expression match on tag
- expression. An example would be
varnishlog -o TxStatus 404to only show log records where the transmitted status is 404 (not found).
While in Brazil, I needed something a bit more expressive. I needed
something that would tell me if I had vcl_recv call pass and the URL
ended in .jpg.
varnishlog -o -c | perl -ne 'BEGIN { $/ = "";} print if
(/RxURL.*jpg$/m and /VCL_call.*recv pass/);'
fixed this for me.
2008-12-15 – Ruby/Gems packaging (it's java all over again)
It is sad to see how people complain about
how packaging Ruby gems is painful. It seems like it is the Java
packaging game all over again where any application ships its
dependencies in a lib/ directory (or in the case of Rails,
vendor/). Mac OS X applications seem to do some of the same thing
by shipping lots of libraries in their application bundle, which is
really just a directory with some magic files in it.
This is of course just like static linking, which we made away with for most software many years ago, mostly due to the pain associated with any kind of security updates.
Update: What I find sad is that people keep making the same mistakes we made and corrected years ago, not that people are complaining about those mistakes.
2008-11-28 – !Internet
qurzaw (0.0.0.0) Fri Nov 28 21:34:28 2008
Keys: Help Display mode Restart statistics Order of fields quit
Last 60 pings
1. 10.125.123.1 ............................................................
2. 10.84.0.1 .??????.......??????.......??????......???????......??????..
3. c9110002.virtua.com.br .????????.....??????..?..?????????..??????????.?..?.??????.?
4. embratel-G2-0-1-ngacc01. .??????.......??????.......??????......???????......??????..
5. ebt-T0-5-5-0-21-tcore01. .??????.......??????.......??????......??????.......??????..
6. 200.230.251.133 .??????.......??????.......??????......??????.......??????.?
7. 200.230.251.154 .??????.......??????....?.???????......??????.......??????..
8. ebt-G4-2-intl03.rjo.embr .??????.......??????......???????......??????.......??????..
9. ebt-ge-5-2-0-intl02.mian .??????......???????......???????......??????.......??????..
10. p4-1-0-3.r01.miamfl02.us .??????......???????...?..???????......??????.?.....??????..
11. xe-1-3-0.r20.miamfl02.us .??????......???????......??????.......??????.....>.??????..
12. as-2.r21.asbnva01.us.bb. .??????......???????......??????.......??????.?...>.??????.
13. po-4.r05.asbnva01.us.bb. ???????.?.????????????...??????????..????????.???.?????????
14. 64.208.110.253 ???????......???????......??????.......??????..?...???????.
15. 208.178.61.66 ???????......???????......??????.......??????......???????.
16. vlan1455-10ge.c1.hmg.osl ???????......??????.......??????.......??????....>.???????.
17. c1.hmg.osl.no.webdealnet ???????......??????.......??????.......??????......???????.
18. vuizook.err.no ??????.......??????.......??????.......??????......??????..
Scale: .:41 ms 1:101 ms 2:161 ms 3:301 ms a:661 ms b:1002 ms c:1602 ms
This is my current internet connectivity. Yay, or something.
2008-11-24 – How to handle reference material in a VCS?
I tend to have a bunch of reference material stored in my home directory. Everything from RFCs, which is trivial to get at again using a quick rsync command (but immensely useful when I want to look up something and am not online) to requirements specifications for systems I made years and years ago.
If I didn’t use a VCS, I would just store those in a directory off my
home directory, to be perused whenever I felt the need. Now, with a VCS
controlling my ~, it feels like I should be able to get rid of those,
and just look them up again if I ever need them. However, this poses a
few problems, such as “how do you keep track of not only what is in a
VCS, but also what has ever been there”. Tools like grep doesn’t work
so well across time, even though git has a grep command too, it still
doesn’t cut it for non-ASCII data formats.
Does anybody have a good solution to this problem? I can’t think I’m the only one who have the need for good tools here.